最近DeepSeek 大火,不少用户也来了解我们公司货代系统与仓库系统是否有接入计划,这里大概分享一下我们了解到的信息.

一,数据蒸馏技术
数据蒸馏技术是通过一系列算法和策略,将原始的、复杂的数据进行去噪、降维、提炼等操作,从而得到更为精炼、有用的数据,以提升训练效率,大幅降低训练成本。
简单但不确切的说,就是在其他AI 的输出的结果上再训练AI 。
所以这并不是完全新的发明,是可以大幅降低成本,效率提升10倍以上的新方法。
二,ERP 系统大模型应用
1,基于知识库的呼叫客服中心,ChatGPT时我们就已提出,像现在机器人打电话水平就比以前提升了很多。而现在成本更低了,以后骚扰电话会更多的。
2,基于图像识别的文档整理与输出,比如托书的识别,但这个功能的应用目前离不开人工干预,像freightX 货运系统创建订单方式在效率上要优于智能识别。
3,基于大数据的报表整理与输出、阙值预测分析、财务审核等功能,数据安全问题目前仍是重点。
4,基于知识库的系统使用帮助文档,目前正在训练其使用freightX 货运系统,但效果并不理想。
5,基于全网实时数据查询,比如船期表、实时运价、码头港区信息等,目前实测无法获取。
三,接口付费
羊毛出在猪身上,狗来买单,这句互联网名言大家应该都听过。
举个例子,你用高德地图是免费的,但不说广告收入类,其他任何APP 通过接口接入高德都是要付钱的,否则就无法实现从另一个APP 直接跳转到高德地图。
接口计费方式多种多样,比如 freightX 货运系统的箱货跟踪接口是按主提单号票数计费;库满么仓库系统的预录接口是按集装箱数量计费;而大语言模型是按 Token 数量来收费的。
Token 是什么呢?
大语言模型(Large Language Models,LLMs)如果想理解自然语义,分词那是基本功,Tokenizer 的意思是分词器,Token大概是这么来的。
Token是文本处理中的最小单位,其类型多样,包括单词级、字符级和子词级,对于中文、日语等没有明显词间分隔符的语言更倾向于字符级或子词级Token。
举例:
一个半/小时/就是/三个/半小时
一个/半小时/就是/三个/半小时
这两句都有5个Tokens,至于 AI 能理解成什么样子,就看大模型训练的到不到位了。
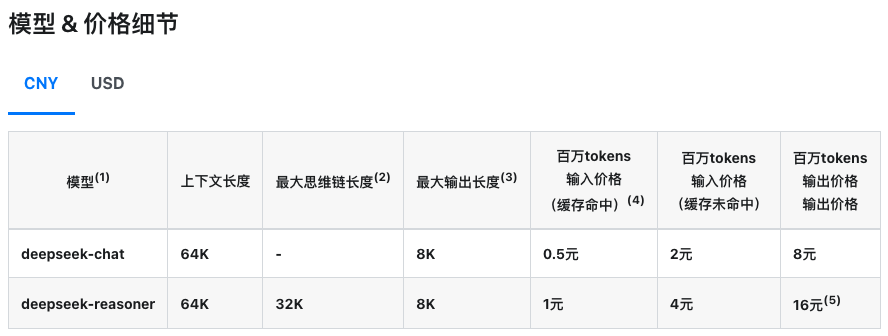
以下为 DeepSeek官网展现接口价格表,注意,提问(输入)与回答(输出)都要收费哟。